RoPE Embeddings
Re-thinking positional embeddings in transformers


Unlike LSTMs/RNNs, self-attention layers in transformers do not inherently take care of tokens’ positional information. Typically, positional information is added to the input token embedding, hoping the model will receive information about the order of the tokens. However, the model could use a different version of positional information — one whose basis is the relative distance of tokens in a sequence instead of their absolute position.
In this article, I discuss Rotary Positional Embedding or RoPE, a way to encode relative positional information.
What is relative positional encoding, and why use it anyway?
If you recollect, transformer architecture encodes the positional information in an embedding, computed as —

The first formulation is for the even positions (2t), and the second is for the odd positions (2t+1). k indicates the index of the element in the d-dimensional embedding.
Note that the embedding is fixed for a particular position in the input sequence. Hence, this kind of positional embedding is called absolute positional embedding. On the contrary, relative embeddings encode information between two positions in the input sequence. Instead of computing a fixed embedding for a standalone position, it works on the relative distance of one position with respect to the other. For example, positional encoding for position 10 with respect to 13 is the same as that of 132 with respect to 135, as the relative distance is the same and equal to 3. How the encoding works is discussed in detail further.
There are a few advantages to using relative positional encoding. During training, the model is exposed to sequences of varying lengths. Typically, the share of extremely long sequences is small. Hence, the exposure to positional embeddings corresponding to large indices is minimal. As a result, the model is under-trained on such positions. However, relative positional embeddings do not depend on the absolute index. This makes them scalable to longer sequences.
Moreover, relative encoding does have an intuitive sense. For example, in the sentence - The cat is under the table, if we use absolute positional embedding, the token cat gets the embedding corresponding to index 1, and the token is gets the embedding for index 2. Now, it's up to the model to figure out that these two embeddings are one place apart, which may be difficult. Remember that this is not a concrete reasoning, just an intuition.
What is RoPE or Rotary Positional Embedding?
This paper discusses a popular way to implement relative positional embedding called RoPE. Particularly, RoPE uses concepts from the theory of complex numbers to encode positional information. Recall that absolute positional encoding adds an embedding to the token embedding and then multiplies it with a key or query matrix to get the key or query embedding. Like -
Where m is the query index, qm is the query embedding, n is the key index, and kn is the key embedding. qm and kn can be used to compute attention score via inner product as
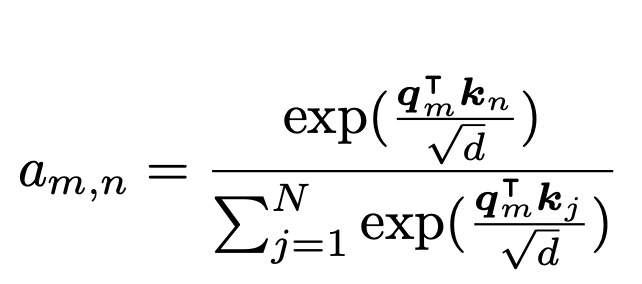
However, RoPE does not do this. Instead, it inserts a multiplicative term straight into inner product computation. This term, called a rotation matrix (the term in bold in the equation below) encodes the relative positional information between the tokens at positions m and n.
You may notice that the term is a function of n-m, or the relative distance between the query and the key positions. It works in the context of two positions and cannot be defined absolutely. We’ll discuss more about where this term comes from and how it makes sense ahead.
What rotation?
It is still not clear why the paper uses the word rotation. Here’s where the theory of complex numbers comes into play. Many of you might be familiar with what I am about to explain. For those who aren’t or have forgotten, here’s a refresher —
A small refresher on complex numbers
A complex number is of the form a + i*b, where a is called the real part, and i*b is called the imaginary part (a and b are real). It can also have a geometric interpretation on a 2-D plane. Let’s take an example complex number 3 + 4i.

In the above figure, 3 + 4i is represented on a 2-D plane. It becomes instantly clear once we treat the real part as the x-axis, the imaginary part as the y-axis and the complex number as the resulting vector. We know that a vector is defined by its magnitude and direction. In this case, the magnitude would be sqrt(3^2 + 4^2) = 5 , and the direction could be defined by θ. θ is computed as acos(3/5). Hence, the complex number can be re-written as 5*(cosθ + i*sinθ). Observe that cosθ + i*sinθ itself is a unit vector as its magnitude (cosθ)^2 + (sinθ)^2 = 1.
Here’s the interesting part — If I want to rotate a complex number by an angle α, all I need to do is multiply it with cosα + i*sinα. Here’s the proof —
Consider a complex number ||A||*(cosθ + i*sinθ). ||A|| is its magnitude, and hence a real number. Multiplying (cosθ + i*sinθ) with cosα + i*sinα (ignore ||A|| for a bit),
(cosθ + i*sinθ) * (cosα + i*sinα) = cosθ*cosα + cosθ*i*sinα + i*sinθ*cosα + i*sinθ*i*sinα
= cosθ*cosα + i*(cosθ*sinα + sinθ*cosα) + (-1)*sinθ*sinα … [since i*i = -1]
= cosθ*cosα - sinθ*sinα + i*(cosθ*sinα + sinθ*cosα)
= cos(θ + α) + i*sin(θ + α)
Bringing back ||A||, the final product is ||A|| * (cos(θ + α) + i*sin(θ + α)). Hence, the original complex number is rotated by an angle α.
The above rotation can be represented as a matrix multiplication as well —

How is that useful?
In the formulation of RoPE, the rotation matrix rotates the query token embedding by an angle proportional to the relative distance n-m, thereby encoding positional information. The further the key token is from the query token, the greater the rotation angle. This makes sense intuitively.
If you observe, you may infer that the rotation matrix must be of the dimension DxD, where D is the dimension of the xk/xq. However, we laid out the concept of rotation in 2-D. So, how does the rotation extend to any arbitrary dimension D?
Formulating the rotation matrix for a dimension D
Extending the idea of positional encoding for a large dimension D is straightforwad — Break D into blocks of 2 dimensional elements. Consider the case where D=4. Consider an embedding x with elements [x1, x2, x3, x4]. Lastly, we assume α is the angle of rotation. We divide x into blocks of 2-D embeddings — [x1, x2]and[x3, x4], and rotate them separately. This looks like —

Technically, the above operation rotates parts of the embedding by a certain angle instead of the entire embedding. However, it does encode information about the relative positions, which the model could use as a signal during training. The above operation could be re-written as a single matrix multiplication operation —

For an embedding dimension D>2, the above figure shows how the rotation matrix looks like. Finally, to extract maximum positional information, having varying angles for different blocks makes sense. As you can see in the figure below, α is different for the two blocks. Moreover, αi is a function of the relative distance m-n and the block index i. This is akin to the absolute positional embeddings where the angle differs for different elements in the same embedding (refer to the formulation at the beginning of the article).

The reason different blocks have different angles is to fit in as much information as possible about the positions. Had the angle been the same, all blocks would rotate by the same amount and would lack diversity. What if positional information in a certain element of the embedding is more important or needs to be represented a little differently than some other element? A constant rotation throughout the embedding won’t be able to encode such nuances efficiently.
Finally, to complete, below is how the paper formulates the rotation matrix —

The figure above depicts a more formal and generalized form of what we discussed.