

[Paper Summary] Monolith: Real Time Recommendation System with Collisionless Embedding Table
How companies like ByteDance (parent company of TikTok) implement realtime machine learning

Paper link
Recommender systems often require adapting to a user’s interest in real-time. In use cases like social media/content, a user’s interest might change every few minutes. A model generating these recommendations must adapt to these fast-changing requirements. Consequently, the model training and serving setup must support real-time training and corresponding real-time inference. Current frameworks like Tensorflow and PyTorch focus mainly on batch training. Once a model is trained on millions of data points, it is exported as a static graph for inference. There is no direct support for changing the parameters of this exported model while generating predictions.
ByteDance created a framework named Monolith that solves this problem. It is a recommender system whose model takes a user’s real-time feedback (feedback can be liking or sharing a video, for example). It computes the loss and the gradients and updates the model parameters in realt-time.
The rest of the article covers the following -
How do real-time training and inference work in Monolith?
Challenges in implementing a real-time model.
What is a collisionless embedding table, and what problem does it solve?
Implementing the real-time model.
Key evaluations and results.
How do real-time training and inference work in Monolith?
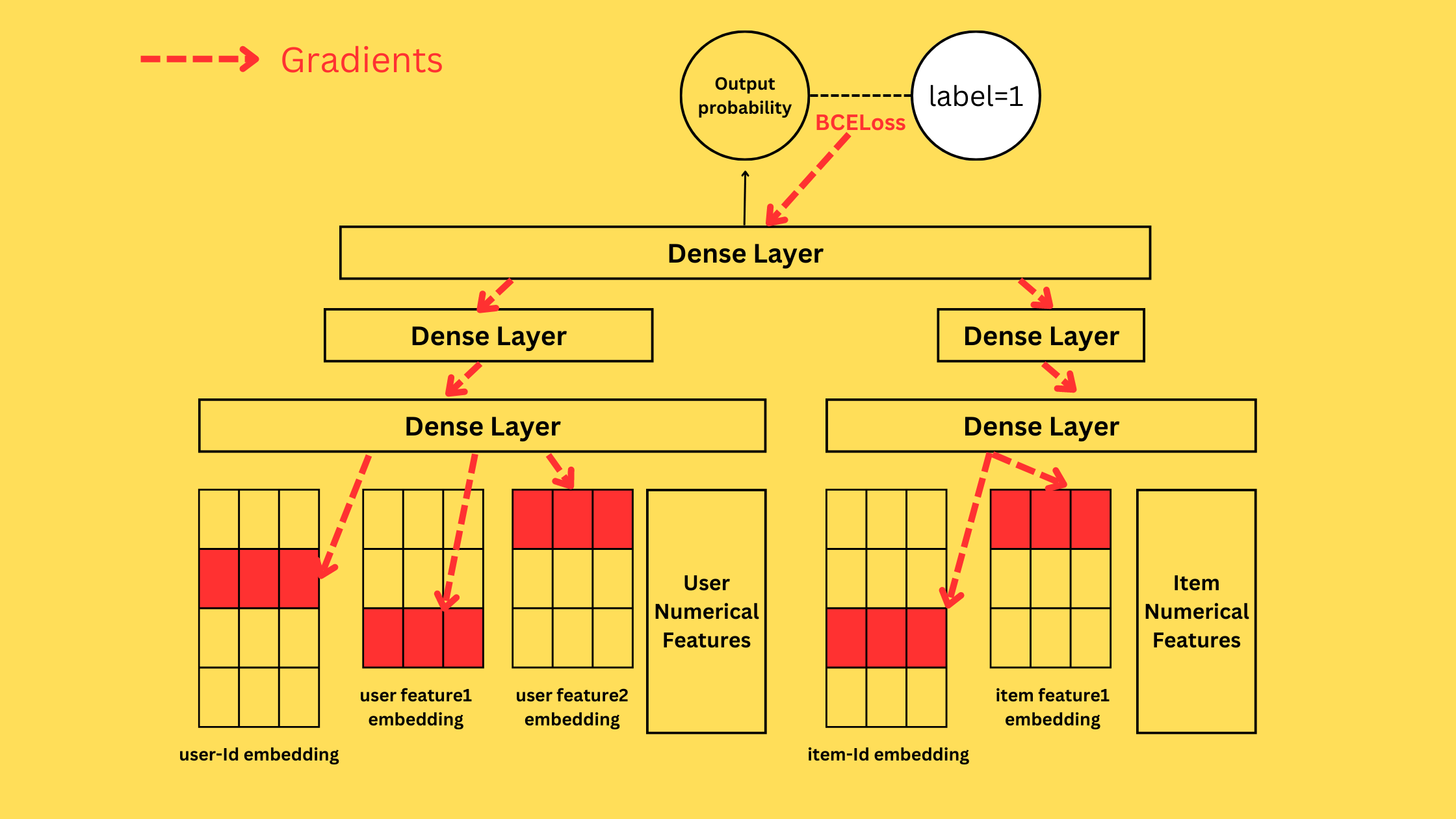
A typical model has two types of input features - numerical and categorical. In recommender models, categorical inputs are represented as low-dimensional embeddings (for example, if the system has 1M users, each user has a 16-dimensional embedding). The size of recommender models is dominated by these embedding table parameters compared to the linear unit parameters.

A model will take features from the user and item to predict the probability of taking action (liking, sharing, following, for example). During training, the loss is computed against the actual action using BCELoss, for instance, and the model parameters, including the embedding table parameters, are updated.
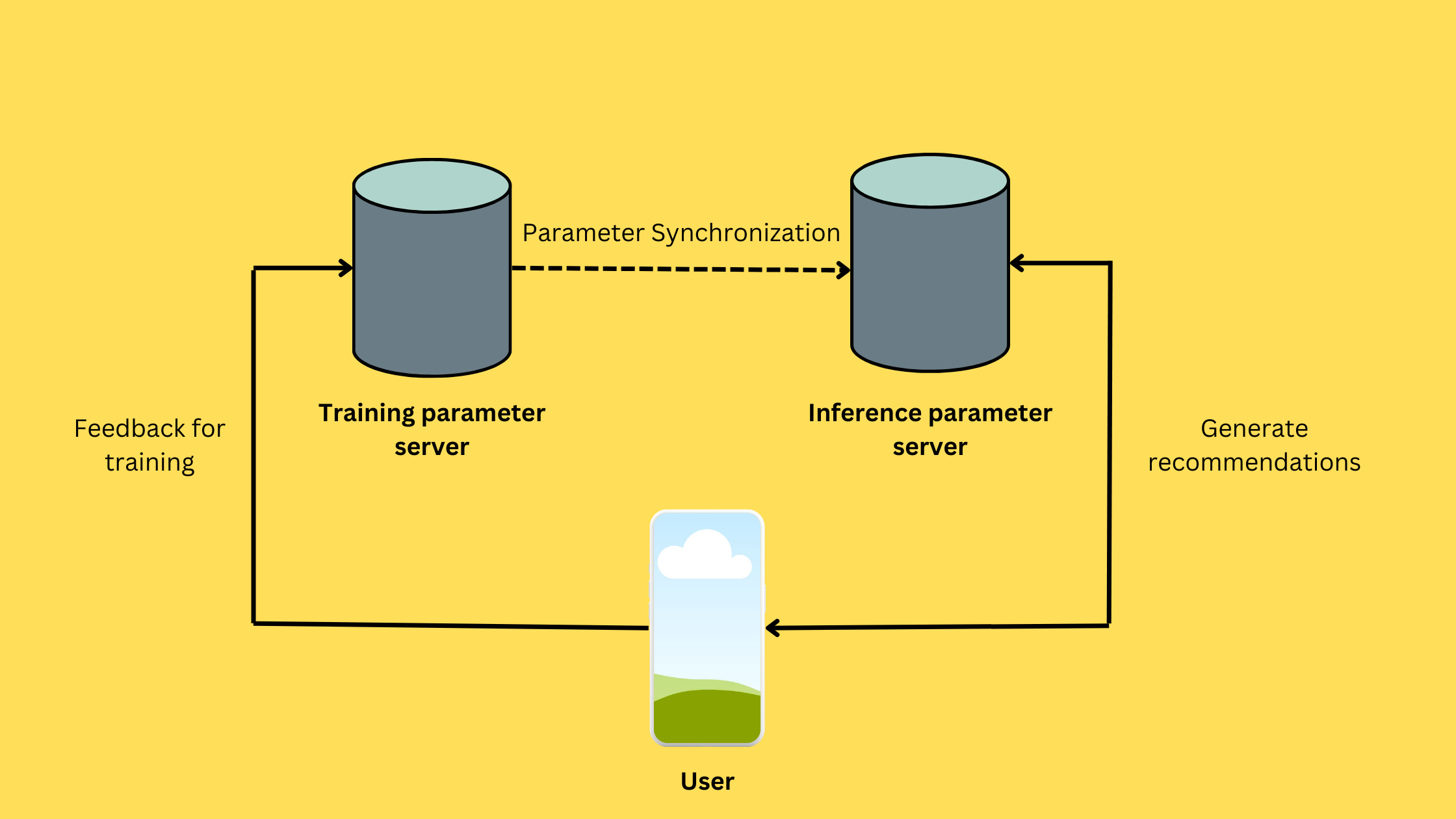
Monolith uses a Parameter-Server (PS) setting to make this process near real-time. A training-PS updates model parameters using the real-time event stream the system collects. This PS trains in real time but does not participate in inference. Monolith also hosts an inference-PS that is used for inference. The inference-PS syncs its parameters with the training-PS periodically.
Challenges
The embedding table size can be enormous. Consider a user-level embedding table for a system having 100M users. Having such a sizeable embedding table is not feasible.
The embedding table grows with time. As new users join the platform, this 100M number can increase quickly.
Syncing training-PS and inference-PS frequently is expensive. Recommender models with such a massive number of embeddings can consume 100s of GBs. Copying it from training-PS to inference-PS is costly and prone to network failures.
If we don’t sync parameters frequently enough, the inference-PS will serve from stale model parameters that can lead to poor recommendations.
What is a collisionless embedding table, and what problem does it solve?
Monolith solves challenges 1. and 2. using the concept of collisionless embedding tables. Consider an embedding table that maps a hashed Id to an embedding.
In a table with collision, an Id with same hash can get mapped to the same embedding.

To get an embedding from an Id, one hashes the Id and looks up the entry corresponding to this hashed Id (% table_size) to obtain the embedding. If the embedding table has a capacity of 10M, the function map Ids uniformly to an integer between 0 and 9999999.
One might wonder what happens in a collisionless table when
Two Ids have the same hash?
More than 10M users try to get an entry in the table? Remember that the user base is ever-growing.
For the first problem, Monolith uses Cuckoo Hashmap. According to the paper -
It maintains two tables 𝑇0, 𝑇1 with different hash functions ℎ0(𝑥), ℎ1(𝑥), and an element would be stored in either one of them. When trying to insert an element 𝐴 into 𝑇0, it first attempts to place 𝐴 at ℎ0(𝐴); If ℎ0(𝐴) is occupied by another element 𝐵, it would evict 𝐵 from 𝑇0 and try inserting 𝐵 into 𝑇1 with the same logic. This process will be repeated until all elements stabilize, or rehash happens when insertion runs into a cycle.

For the second problem, the authors argue that a small percentage of users have disproportionate activity on the platform, and many users have scant activity. Embeddings for these less active users often underfit due to fewer training examples. Moreover, these users don’t affect platform-level metrics so much. Similarly, an item or a video gets older and gains less traction over time. In such cases, it is wise to drop their embeddings to avoid the embedding table growing massively over time. Consequently, although the user base grows, Monolith proposes a mechanism to retire stale and scarcely used embeddings. This keeps the embedding table size in check.
Implementing the real-time model
Although the goal of Monolith is to implement real-time training and inference, it starts with batch training. As soon as this batch training finishes, the real-time training kicks in. Think of batch training as an initial checkpoint to start the real-time training.
Monolith needs a stream of user events (clicks, likes, etc.) to perform real-time training. The model might also need features corresponding to these events (timestamp of the event, the language of the item/video/post, etc.). Monolith uses two Kafka queues to supply events and features. A Flink job joins the event with its corresponding features. Each request is assigned a unique key to ensuring the event is joined with the correct features.

Parameter Synchronization
The most crucial aspect of real-time training is ensuring that training-PS and inference-PS are in sync and the lag in synchronization is as small as possible. Two key challenges the paper reports are
The model must not stop serving when the synchronization is ongoing.
Model sizes are enormous due to large embedding tables. This puts strain on the network bandwidth.
However, a relatively small number of Ids get updated between two synchronisation cycles. In addition, the dense parameters move slowly compared to the sparse parameters. This is because they get non-zero gradients for every data point, while only one Id in each sparse embedding table receive updates.
Monolith maintains records of the Ids that were updated after a synchronization cycle and updates only those embeddings in the inference-PS corresponding to these Ids. And because the dense parameters move slowly, their update schedule is less frequent than the Id-based embeddings.
To make the model fault-tolerant, Monolith snapshots the training-PS every 24 hours. Although more frequent snapshots lead to less stale models during recovery, the 24-hour schedule is a good tradeoff between cost and the drop in model performance.
Key evaluations and results
The paper evaluates the following -
The benefit of using a collisionless embedding table
The authors assessed Monolith on the MovieLens dataset that contains 25M ratings for 162K users and 62K movies. They use MD5 hashing to get an estimate of the collision rate.

In a table that allows collisions, two Ids with the same hash share an embedding. Authors report that a collisionless table performs consistently better than a table with collision across epochs and across days (training happens every 24 hours on fresh events)
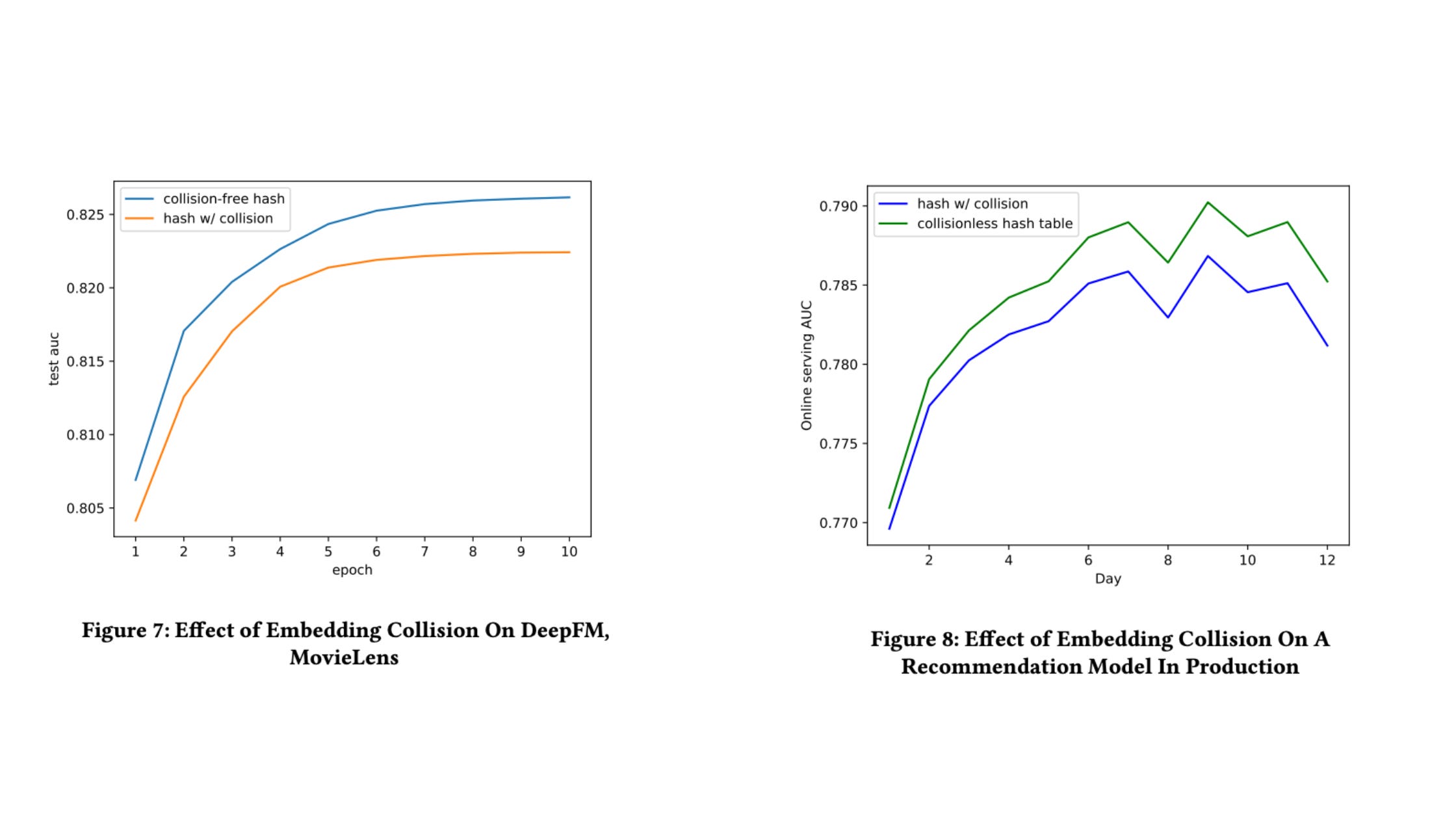
Clearly, collisionless embedding tables perform consistently better.
The benefit of online training and larger synchronization frequency
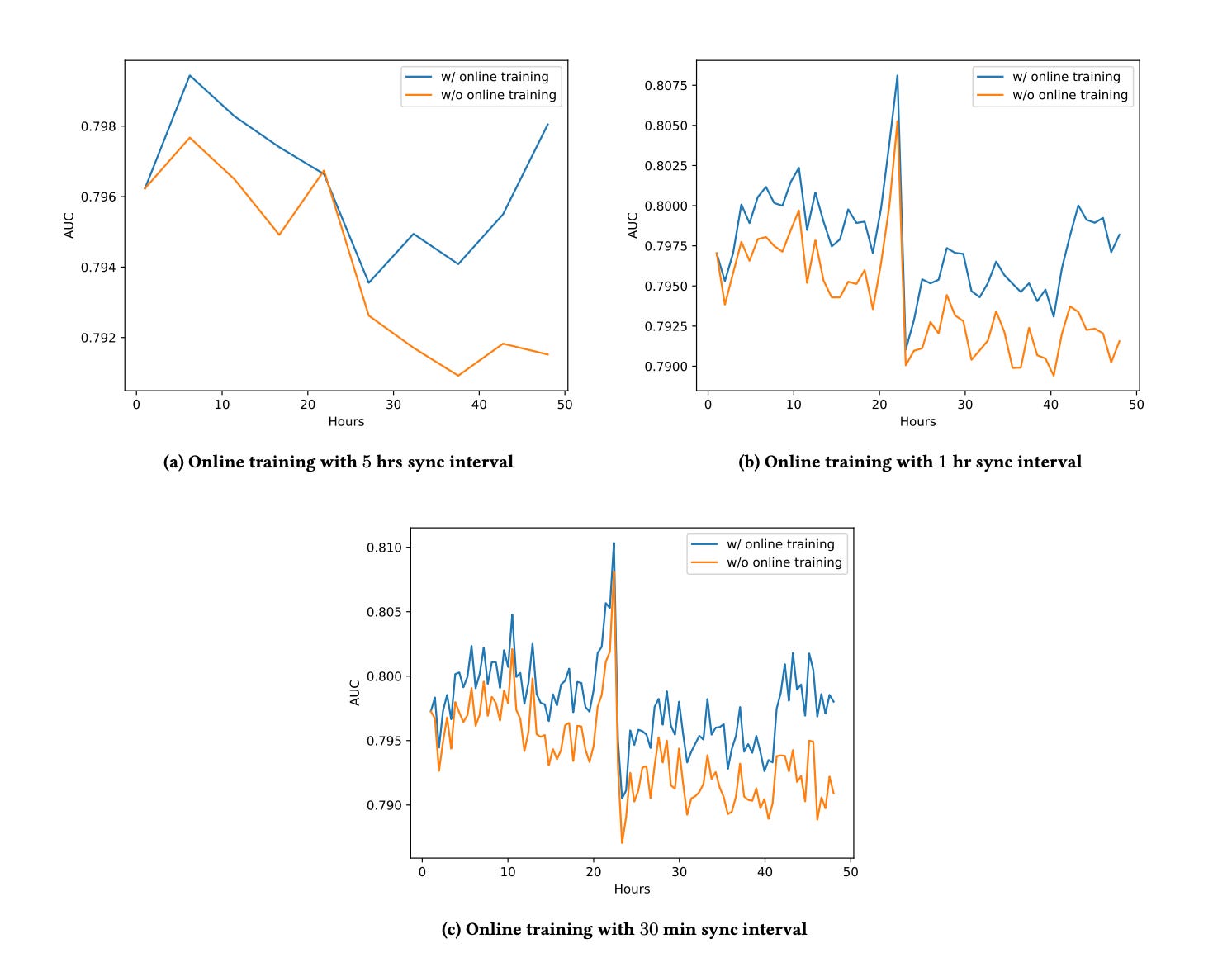
The authors evaluated the benefit of training a model in real-time vs training a model in batch on the Criteo Ads dataset. Simultaneously, they experimented with three synchronization intervals - 30 minutes, 1 hour and 5 hours.
In all 3 cases, real-time training outperforms batch training. Moreover, as expected, 30 min interval best retains the metrics, followed by 1 hour and then 5 hours.
Final thoughts
The authors have open-sourced the code for anyone to try. Overall, I like that the paper focuses on finer implementation details. In my opinion, engineering in recommender systems might be more if not equally important as training a new SOTA model.
Let me know if you want me to summarize more papers. Suggestions are much appreciated.
Wonderfully articulated summary. Thanks Dhruvil.