How do parameter servers work?
How parameter servers work in synchronous and asynchronous settings

What you (might) already know
A deep neural network can be trained faster on multiple GPUs. Instead of training it on a single GPU with a batch of size B, it can be trained on multiple GPUs, each processing a different batch of size B simultaneously. Hence, the effective batch size is N*B for N GPUs. This is called data-parallel training.
A closer look at multi-GPU training
Consider a model trained on 2 GPUs. Initially, each GPU worker carries a replica of the model and its weights. Both workers read different batches of data and perform forward passes. The objective function is used to compute the loss against the ground truth. Now, in the backward pass, each worker computes the gradients. Naturally, the gradients are different since each worker processed a different batch. However, if the worker updates the parameters using their respective gradients, they will end up with different weights.

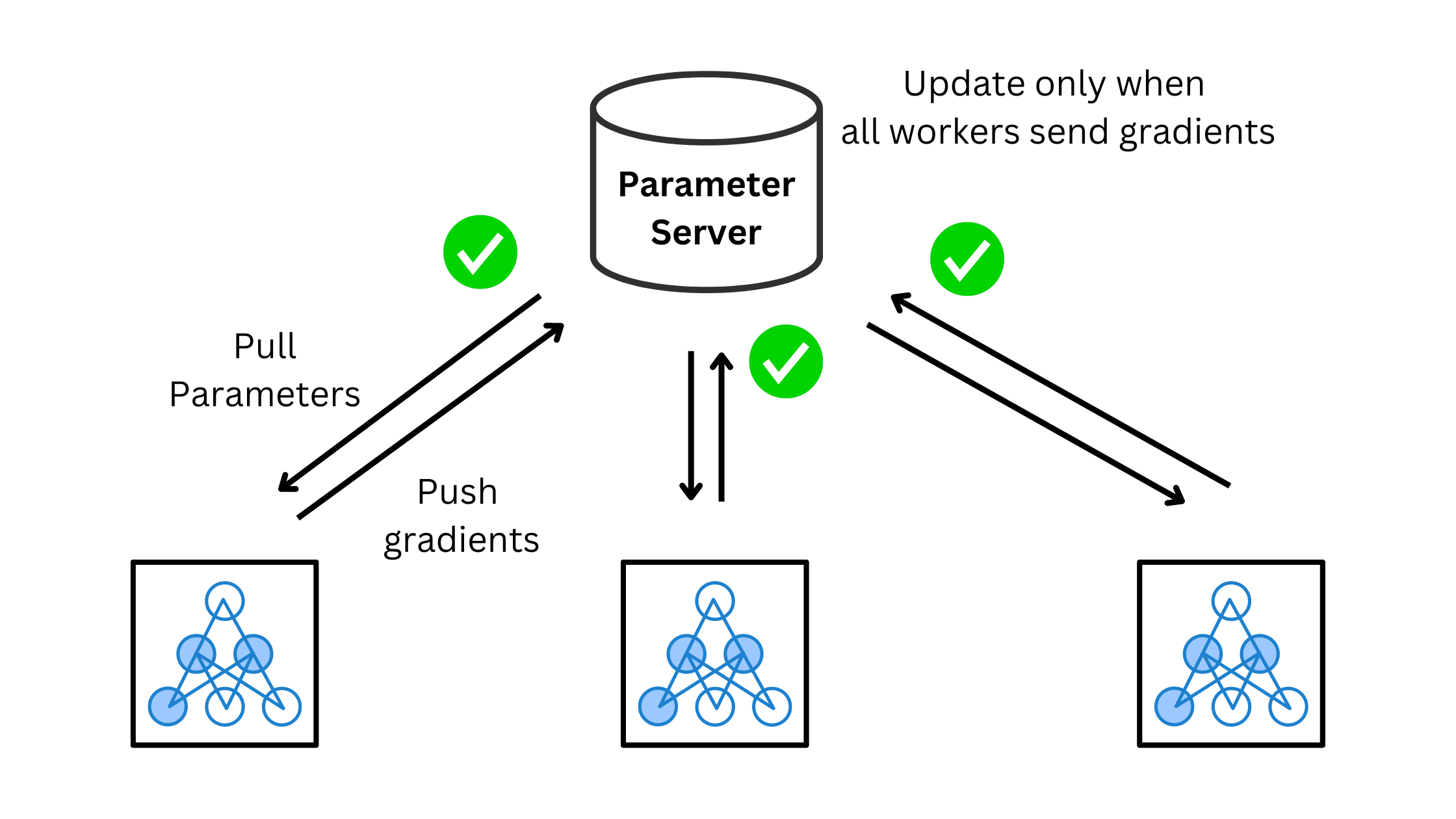
Synchronous training
What are we missing in the above training procedure?
We can’t have multiple models. We need a master set of weights to perform our updates on. Before training on a new batch, the worker must ensure its model copy is consistent with this master. This master is the parameter server (PS). Before making a forward-backward pass on a new batch, it pulls a copy of the model weights from the PS. Next, it computes the gradients and pushes them to the PS. Ultimately, the PS collects the workers' gradients and updates the model weights. The process repeats and now the model trains in a non-divergent manner, as the update step and the weights are centralized, making it synchronous. Each worker waits for everyone else to finish.
Asynchronous training
In a synchronous setting, the speed of iterations depends on the slowest worker. The other workers must sit idle until the last worker pushes its gradients. Such underutilization is not desirable.
The idea behind asynchronous training is to exchange the perfect SGD training provided by synchronous training for extreme resource utilization and, hence convergence speed. Can one achieve the same metrics and convergence quickly?
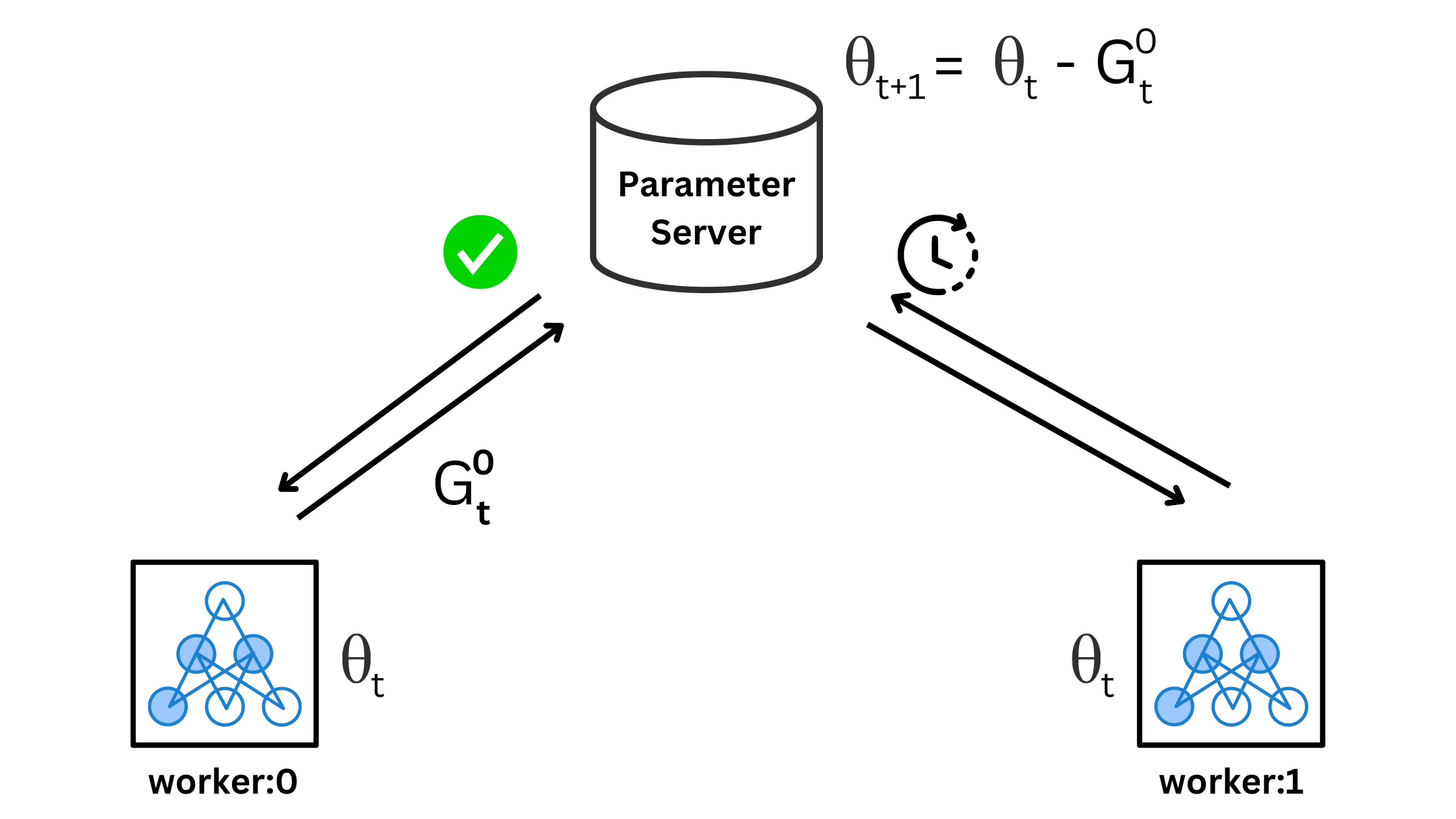
In asynchronous training, each worker acts independently. A worker and the PS don’t wait for other workers to push their gradients. The moment PS gets gradients from a worker, it updates the model weights. Just like synchronous training, each worker must pull the latest weights before computing the gradients. Let’s examine this step by step. Consider a PS with weights θ, 2 workers, each processing a batch of size B. Initially, both the workers have the same weights as the PS.
Suppose worker #0 is the first to process a batch and send gradients to the PS. The PS uses the gradients to update the weights as
(The subscript t on G denotes the weights used at step t to compute the gradients. The superscript denotes the worker index.)
As soon as PS updated the weights, worker #1 sent its gradients too. The PS updates its weights again as
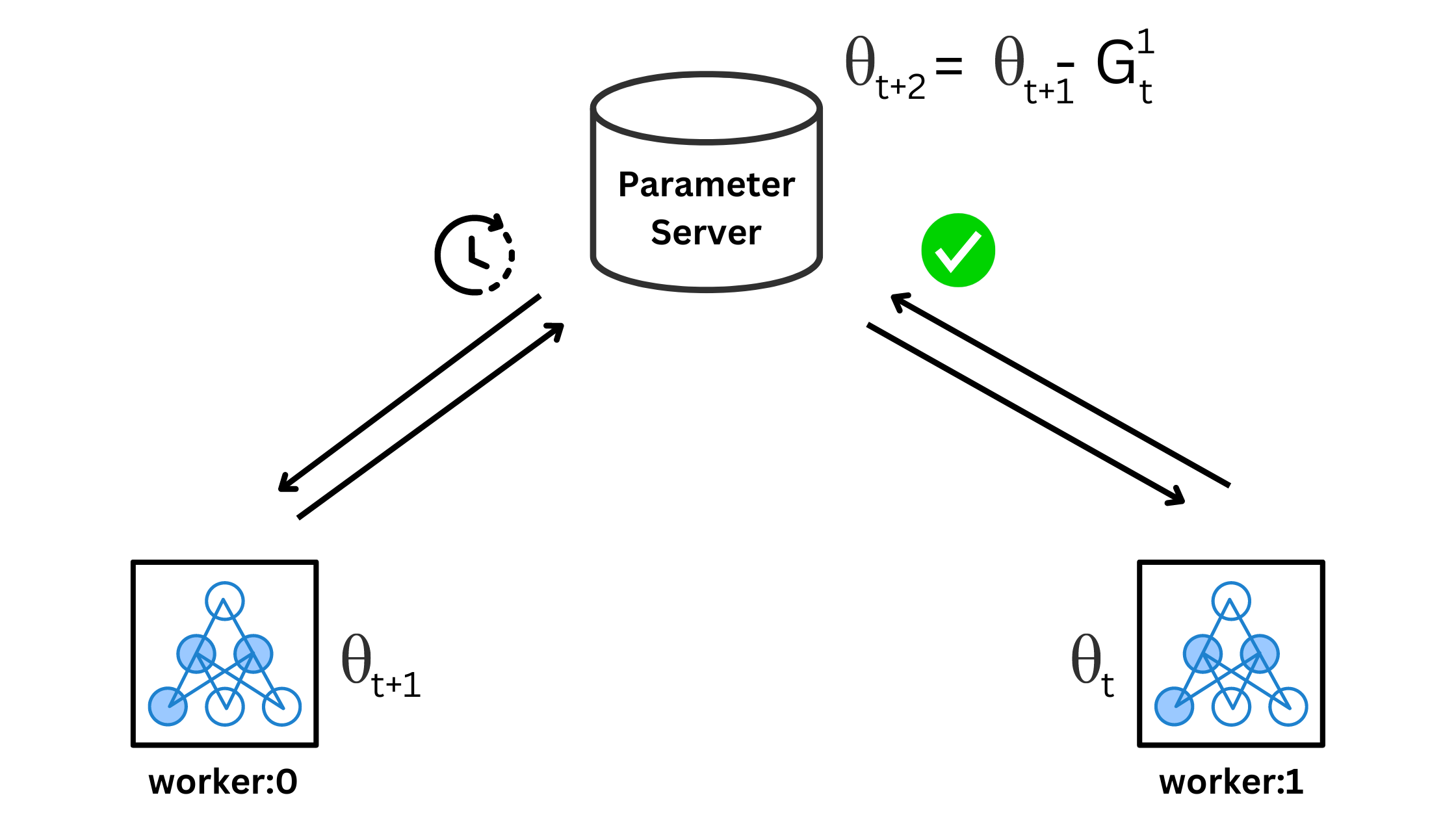
It is highly possible that worker #0 started working on its second batch by pulling weights θt+1 since the PS was not done with the above update. Hence, the gradients produced are based on θt+1, although θt+2 was available. Worker #1 not waiting for θt+2 is the asynchronous part. Now, when worker #1 sends its parameters, the weights update as -
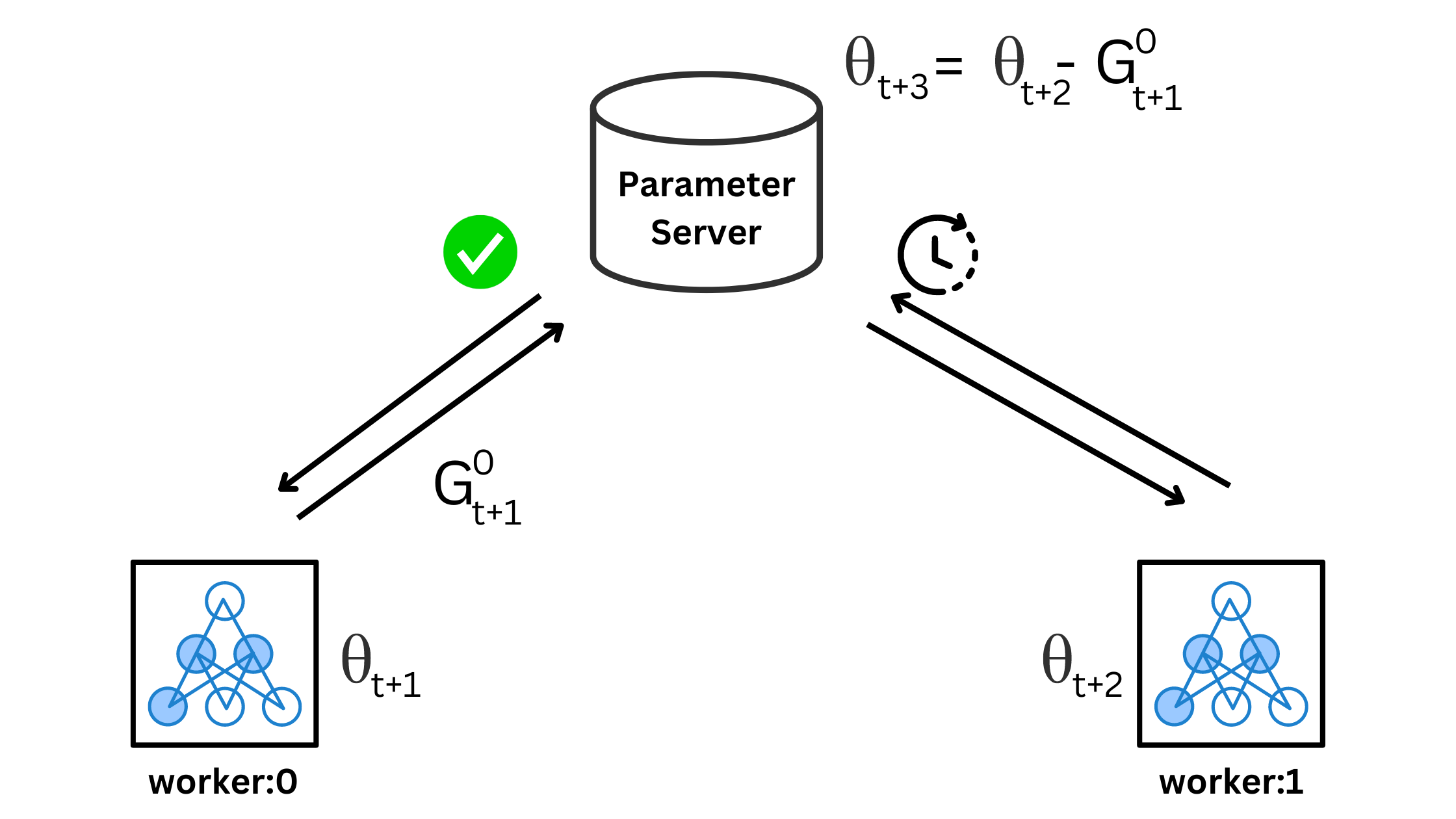
Although a worker might not use the latest weights, the centralized weights keep updating.
The problem arises when a worker's weights to compute gradients are stale. When a worker pulls weights and takes too long to compute gradients, the PS already updates the weights many times based on pushes from other workers. Hence, the gradients from this particular worker are not just relevant but harmful, as the update might take the model weights in a sub-optimal direction. This is one reason why using a smaller learning rate in asynchronous training is recommended. It curbs the effect of stale gradients.